
Fine-tuning or RAG: Which LLM Strategy is Best for Your GenAI Model?
Developer

Almost five years ago, Patrick Lewis and his team introduced a groundbreaking approach called Retrieval-Augmented Generation (RAG). This method combines generative capabilities with an external retrieval mechanism, enabling models to produce highly accurate and contextually relevant responses. By integrating dynamic, real-time knowledge retrieval, RAG addresses key challenges associated with traditional LLMs, such as hallucination and limited knowledge scope.
In one of our AI projects, we are developing an intelligent tool specifically designed for the real estate domain. This tool analyzes the content of user documents, such as appraisal reports, against official rules and regulations that define their structure, content, and format. It generates a list of discrepancies, violations, or inaccuracies and provides explanations for the issues or highlights missing information.
Our current implementation fine-tuning or RAG uses RAG to find relevant rules based on the user report section and include this information in the system prompt. This narrows the scope and improves accuracy.
Challenges in Managing Costs and Efficiency
The tool works well, but the analysis cost is high due to:
- Large input documents: Appraisal reports often exceed 100 pages.
- Lengthy regulations: Reference documents are around 50 pages long.
This leads to large prompts (100-120k tokens) and increased processing time. Our goal is to reduce both token usage and latency.
Proposed Solution: Fine-Tuning for Enhanced Efficiency
We considered fine-tuning or RAG to optimize an existing GPT model on our real estate knowledge base. This capability, recently introduced by Azure OpenAI Service, allows for customizing models with specific data. We hypothesized that fine-tuning would enhance performance and reduce prompt sizes by eliminating the need to include lengthy rule texts in each request.
Fine-tuning Process
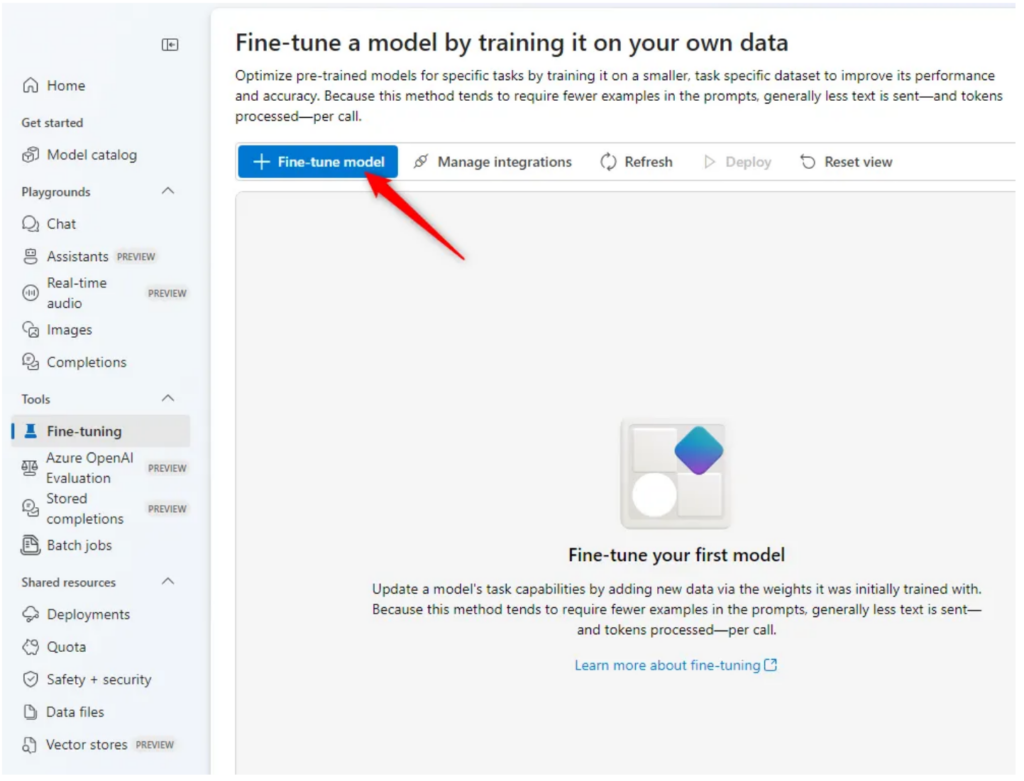
In Azure AI Foundry, the entire fine-tuning process is straightforward: you simply go to the Fine-tuning menu and follow a few simple steps:
- Select a base model and fine-tuning method.
- Upload training data.
- Upload validation data (optional).
- Start the training.
- Deploy the model.
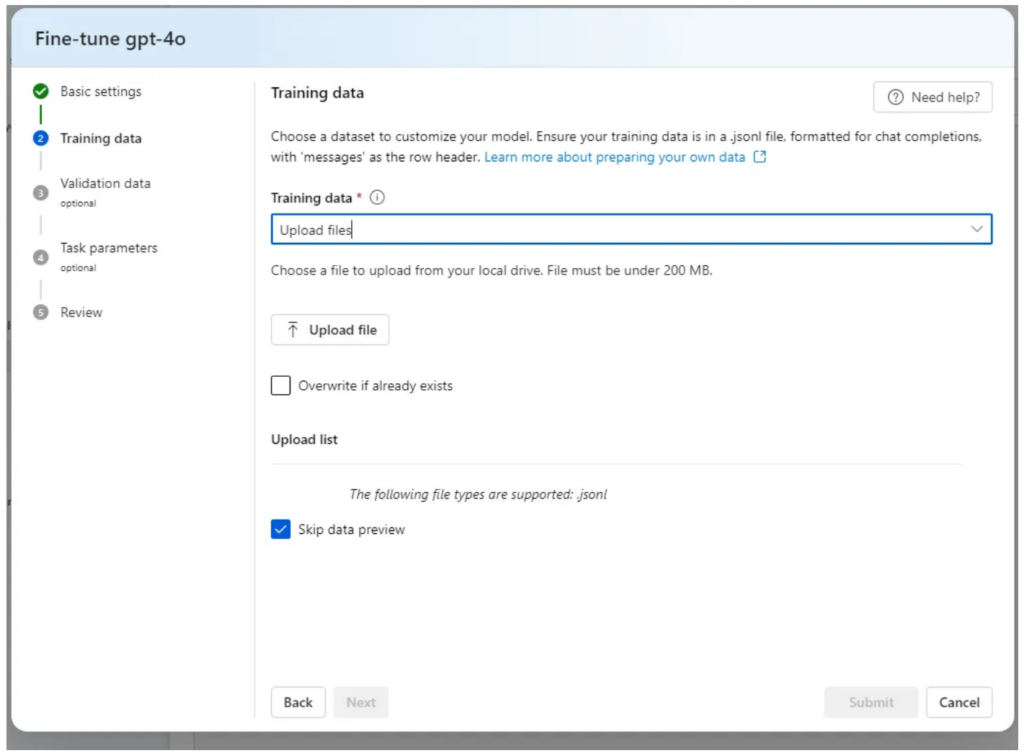
Training Data Preparation
Preparing the training data is the most crucial and time-consuming aspect of the fine-tuning process. OpenAI requires the data to be formatted in the following structure:

We knew our initial approach of just giving the model general knowledge wouldn’t cut it for fine-tuning. Fine-tuning needs lots of specific examples for each task – in our case, we’d need at least 10 examples for each thing our AI tool does. Each example has to have:
- A task description in the “system message” section.
- Relevant text from the user report and regulations in the “user message” section.
- The desired output in the “assistant message” section.
Even though we knew this, we decided to go ahead with a simplified “general knowledge” approach for our first round of tests.

We applied this simplified approach to each USPAP regulation to see if the LLM would actually use the provided text when it generated its responses.
Deployment and Tests
Even though we only used 50 training examples (12k tokens), training was quick and only took 2 hours. Deployment of the fine-tuned model was also fast (5 minutes). Unfortunately, our final tests were disappointing. As we expected, the simplified training data wasn’t enough. Without the original regulation text in the prompts, the model’s answers were less accurate than those from the RAG approach with the default model. Even worse, it made up rule section numbers that didn’t exist. Our attempt to replace RAG with a minimally trained fine-tuned model didn’t work.
Important Outcomes
- Cost
- Once you deploy the fine-tuned model, Azure charges $40 per day to keep it running in the cloud. This is a substantial cost and needs careful thought, as it might only make sense for long-term projects with high LLM usage.
- Training Data
- This is arguably the most critical factor impacting the quality of a fine-tuned model. Just giving the model a ton of raw data (“brute-force feeding”) isn’t enough. In our case, this approach didn’t lead to good results across different tasks. Instead, you have to carefully prepare the training data for each task, giving clear inputs and the results you want.
- Maintainability
- Even with a well-trained model, keeping the underlying data up-to-date can be tough. Every data update means you have to adjust the training data, retrain the model (which costs more), and redeploy it. In these situations, the RAG approach is more flexible and cost-effective.
- Suitability
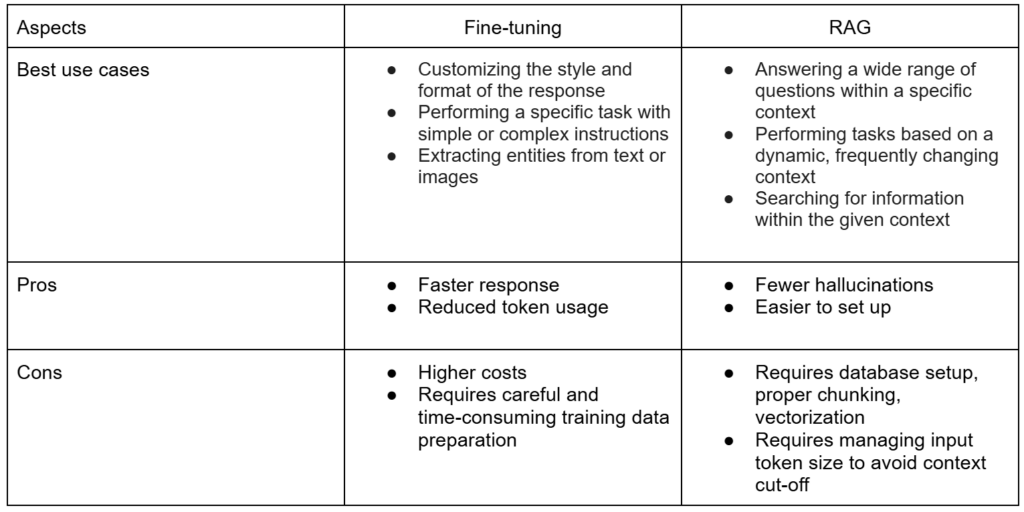
- Fine-tuning isn’t as effective for teaching general knowledge and expecting the model to answer a wide range of questions based on that knowledge. RAG is better for this. However, fine-tuning can be more efficient in terms of time and token usage when you’re aiming for specific output styles, formats, or highly specialized tasks. This is because fine-tuning eliminates the need to include formatting instructions or input-output examples in every prompt.
Embracing the Right Tool for the Job
The Future of Fine-tuning and RAG for AI Models
The choice between fine-tuning and RAG is not about one replacing the other but rather about leveraging their unique strengths for specific needs. Fine-tuning excels at delivering custom outputs, achieving task-specific results, and ensuring efficiency in formatting and style. However, it presents challenges such as high costs, ongoing maintenance, and limited applicability for broad knowledge-based queries.
Conversely, RAG shines in scenarios requiring adaptability, lower costs, and the ability to handle diverse and complex queries grounded in extensive knowledge bases. It offers flexibility and avoids constant retraining, making it ideal for dynamic data environments.
By understanding these trade-offs, businesses can strategically integrate both approaches, optimizing their LLM applications for performance, scalability, and relevance. Ultimately, success lies in aligning the chosen tool with the specific needs and goals of each project, ensuring a balance of innovation and practicality.
Learn more about our RAG implementation services and Advanced RAG capabilities. Contact us today to discuss your project and take the next step toward innovation with confidence!