Three Concepts That Will Change Your Approach to AI System Evaluation
Gen AI QA Director

Imagine you walk into a restaurant, order a steak, and it comes out raw. You complain to the manager, and he sends the chef to a meat-sourcing course. The problem is in the cooking, but they are treating the supply chain. Absurd? Yes. But this is exactly what happens far too often with teams that start testing an AI product, especially when they look for problems in the wrong place, spend weeks optimizing what does not need optimizing, and end up with a system that works no better than it did before all that effort.
When generative AI models entered our profession, most AI and QA specialists found themselves facing a difficult question about how to even test these systems. A neural network does not follow a rigid algorithm. It has no deterministic answer, and it can respond slightly differently each time and still be “correct.” Familiar approaches stopped working at full strength, and no one was particularly explaining the new ones. At best, teams hired human evaluators who manually reviewed responses and assigned scores, but that approach is expensive, slow, and does not scale. At worst, quality was checked on the principle: “We clicked, we looked, it seems fine, let’s move on.”
In this article, we’ll break down three fundamental concepts that help bring order to AI evaluation:
- the AI testing pyramid
- the composite evaluation pipeline
- the Eval-Driven Development methodology
Each one answers a specific question about where to look for the problem, how to measure it, and how not to lose progress along the way. Together they form a system you can work with deliberately rather than blindly. Most importantly, this system is equally useful for an experienced AI engineer and for a developer who has only just started thinking about the quality of their AI product.
Where Did It Break?
Any AI system commonly has a three-level structure, which I call the AI testing pyramid, where each level has its own problems, and mixing them up is a guaranteed way to lose time.
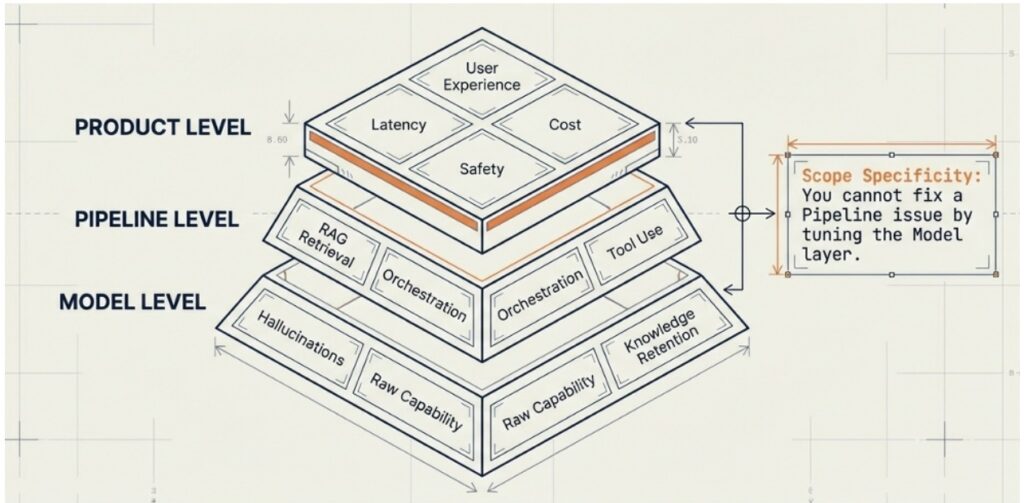
The Model Level is the lowest foundation of the entire construction. This is where the LLM itself lives with its raw capabilities, the knowledge embedded in it during training, its tendency toward hallucinations, and its ability to maintain context over a long conversation. This is what the model can do by default, regardless of how you use it, what prompt you wrote, or what architecture you built around it. If the model does not understand the required language at the required level, or systematically invents nonexistent facts, or loses the thread of the conversation by the fifth message, that is a model-level problem. It cannot be solved with a smarter prompt.
How can we solve these problems? First, by choosing a model that is better suited for your task. Second, through fine-tuning or adjusting the model on specific data from your subject domain. Third, in truly exceptional cases, prompt engineering can compensate for weaknesses of the base model, though this method works more at the pipeline level. It is important to understand that these methods are not interchangeable; if a model has a fundamental limitation in understanding legal texts, no prompt will turn it into a lawyer.
The Pipeline Level is the middle floor, the architectural one. This is where all the components you build around the model live so that it works in your specific product. This includes RAG retrieval (Retrieval-Augmented Generation), the system that searches for relevant fragments from your knowledge base and feeds them into the model’s context before each response. It also includes request orchestration: how your system manages the sequence of model calls. There are tools that the model calls inside an AI agent, such as catalog search, database queries, and email sending. Finally, there are the prompt chains that guide the model through complex multi-step tasks.
If your AI assistant in an online store repeatedly finds the wrong product in the catalog, the retrieval is most likely broken. Perhaps the index is outdated, the embeddings are poorly tuned for your subject domain, or the result ranking logic is pulling up irrelevant items. The model itself may be perfectly fine, because it is working with the context it was given and generating a reasonable answer based on incorrect data. This is exactly why rewriting the system prompt in such a situation is pointless, because you are improving instructions for an employee who has no access to the right information.
The Product Level is the top floor, closest to the user. This is where response latency lives, as well as the cost of each API request, system security, and most importantly—the final user experience. The customer does not know how many floors you have, which model you are using, or how cleverly your retrieval is set up. All they know is whether this chatbot helped them solve their problem, how long it took, whether the bot said anything strange or inappropriate.
Product-level problems often masquerade as model-level ones. A team sees that users are unhappy with the bot’s responses and starts switching to a more powerful model, but the real reason is that the bot takes eight seconds to respond and users simply do not read the answer all the way through. Or, the bot gives correct answers but to questions outside its area of responsibility, and that creates business risks even if the model is technically doing everything right. Security, cost, speed, and experience are product metrics, and they need to be addressed at the product level through caching, security filters, and UX layer optimization.
The key takeaway of this concept is that you cannot fix a pipeline problem by tuning the model, just as you cannot fix a model problem by improving the product interface. This sounds obvious, but in practice it is violated constantly, because not every team has a clear understanding of which level should solve a given problem.
Let’s look at a few typical mistakes. An assistant displays outdated product prices, and the team rewrites the system prompt with the instruction to always show current prices, even though the real problem is that the RAG retrieval is pulling data from a week-old cache. Users complain about slow responses, and the team switches to a faster but less accurate model, even though the latency is caused by the pipeline architecture with unnecessary intermediate calls. The bot sometimes answers questions about competitors, and the team adds a stricter system prompt, even though the solution is a security filter at the product level that should intercept such requests before they reach the model.
Before looking for a solution, always ask yourself the question: which level owns this problem? That will take five minutes, but save weeks of work. And to answer that question with confidence, you need the next tool, the measurement system.
The Evaluation Process Around the AI System Pyramid
Suppose you have localized the problem and understood that it lives at the pipeline level, specifically in the retrieval. Now you need to measure it to understand its severity, the scenarios it shows up, and whether things improved after the changes. This is where traditional testing hits a wall, because a neural network has no reference answer that can be compared (byte by byte) the way a string is compared in a regular unit test.
The Composite Eval Pipeline is an approach that offers not a single measurement tool but several layers of checks built on the principle of a funnel. Simply put, this is like the security system at an airport, where first comes the metal detector frame for everyone without exceptions, because it is fast and cheap. Then comes a manual check only for those who triggered the frame because it is slower and requires human involvement. Only the most complex cases require a full interview with a security officer, because that takes a lot of time and resources. This system is effective precisely because each level does its own job without overloading the next one.
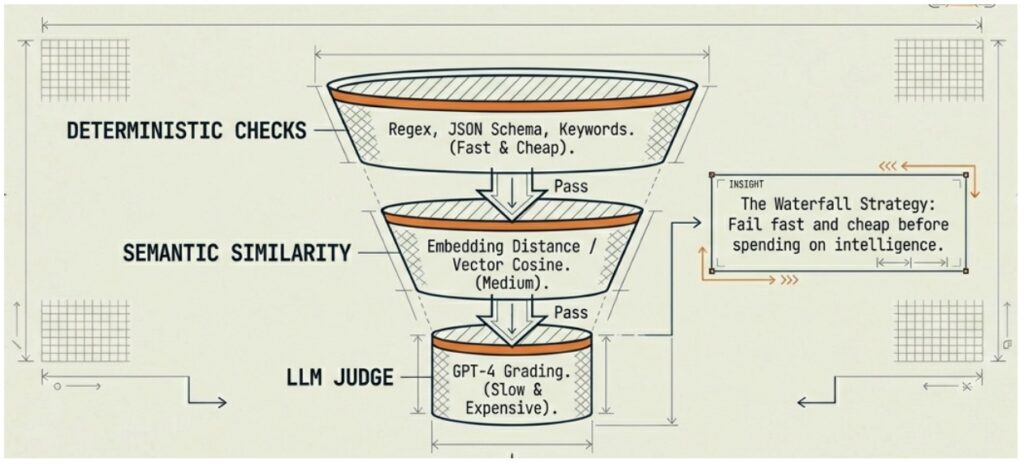
The first level of the funnel consists of deterministic checks. These are fast and cheap automated tests that require no “intelligence” to run, e.g., checking compliance with a JSON schema, regular expressions for searching prohibited patterns, the presence of required keywords, response length checks, and date and number format validation. The majority of obviously broken responses are filtered out at this level without spending a single second of expensive time on subsequent stages. This matters because in real systems such “rough” errors occur unexpectedly often, especially when a model version changes, a prompt is modified, or a new tool is connected to the pipeline.
The second level is semantic similarity. Responses that passed the first filter are compared against reference examples using embeddings, which are mathematical vector representations of text meaning. This is no longer a character-by-character string comparison but a comparison of meanings, measuring how close two texts are in their essence even if they are written in completely different words. Simply put, embeddings are like a coordinate system for meanings. Each text is turned into a point in a multidimensional space, and texts that are close in meaning end up near each other. “There are three items in the cart” and “The customer added three positions” will end up in the same neighborhood of that space even without sharing a single word. And “there are three items in the cart” and “delivery will take two days” will end up far apart, because they are talking about completely different things.
For quality evaluation this works as follows. You prepare a set of test questions and for each of them you need to define a reference answer which is showing how it should ideally look. Then using both, actual AI response and reference answer, you calculate the cosine similarity of the vectors, and if the similarity is above the threshold the answer is counted as correct. If is below the threshold, it moves further down the funnel for a deeper check.
This check is more expensive than the first level because it requires calling an embeddings model for each response. However, it is still orders of magnitude cheaper and faster than the third level, and at the same time capable of catching semantic errors that deterministic checks cannot see. For example, a response may be technically correct in format but focused on the wrong topic, and the semantic similarity with the reference will be low, which is immediately visible.
The third level is the LLM Judge. Only those responses that passed previous filters and still raise questions or those sitting in a “gray zone” by semantic similarity or requiring evaluation of nuances reach the language model evaluator. The LLM Judge is already capable of assessing what mathematics cannot e.g., how useful the response is in the context of the question, and whether it misleads the user indirectly, matches the brand’s tone, and contains hidden logical contradictions. This is slow because calling a powerful model takes time and costs money, because the cost of an API call is significantly higher than for embeddings. This is exactly why only a small percentage of all requests end up here: those that the lower levels could not evaluate conclusively.
There is one important practical point here, which is that the LLM Judge works significantly better when given clear evaluation criterion rather than simply being asked to “assess quality.” Instead of the vague question ( is it a good response?), it is more effective to ask whether this response contains all the information from the following list of criteria, whether it answers only the question asked without adding anything extra, and whether it contradicts the return policy described below. The more specific the task, the more reliable the evaluation.
It is important to understand that this pipeline does not have to be exactly three levels. In some systems, two levels are enough, such as deterministic checks and an LLM Judge without the intermediate semantic similarity. In other systems, there may be four levels with additional specialized checks. The principle is one, where cheap checks go first, and expensive ones go last, and each level passes forward only what it could not evaluate conclusively on its own. This is the waterfall.
Dataset First, Then Development
Suppose you have learned to find problems using various evaluation methods within the composite pipeline: what happens next? You find a problem, improve the prompt, run a few tests manually, see that things have gotten better, and push the change to production. A week later a colleague comes along, adds new functionality, and slightly modifies the same prompt. Another week later someone updates the model version. As a result, a month later your fix has effectively stopped working because several subsequent changes neutralized it. But nobody notices, because nobody is measuring.
This is called “vibe-checking” or the evaluation of an AI system by feel, without a measurable baseline, history, and any way to compare before and after. And this is arguably the most common problem in teams working with generative products, not because the people on those teams are bad engineers, but because they have no methodology that would make changes visible and reversible.
Eval-Driven Development (EDD) is a methodology for developing AI systems in which any change to the system is always accompanied by automated evaluations that were written before the change was made. Simply put, this is the same thing as TDD (Test-Driven Development) in classical programming.
To understand the difference, let us recall how TDD works. The developer first writes a test that describes the desired behavior of the code, and the test fails because the code has not been written yet. Then the developer writes the code so that the test passes. Then they refactor, confirm that the test is still green, and only then consider the task complete. The key point here is that the test is written before the code, and it does not know how the code will be structured internally. This guarantees honesty because in this case the test checks behavior, not implementation.
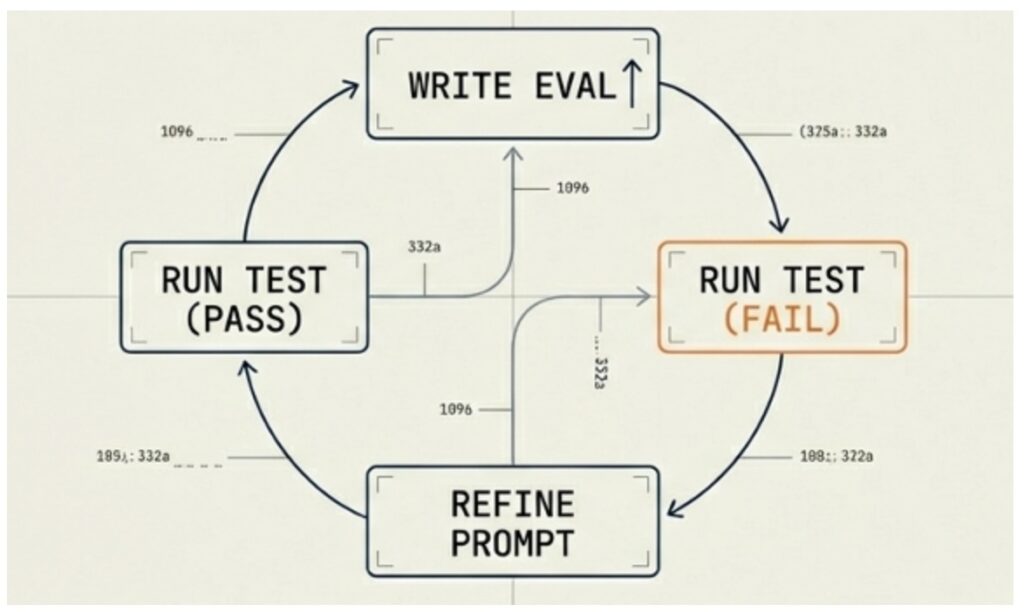
EDD works on the same logic, but instead of unit tests there are evaluation datasets, and instead of assert there are results from the composite pipeline, which we covered in the previous section. You describe what data you will use to evaluate the system before you start changing anything, and then you run the eval and get a failure because the new functionality has not been implemented yet or the current prompt cannot handle it. Then you refine the system and run the eval again. If the test passes, the change is locked in. If not, the cycle repeats.
There is one fundamentally important nuance here that is easy to miss: the eval data or tests must be written before the change, not after. This feels inconvenient; why test something that does not exist yet? But this is precisely the point of the approach.
Evaluation data written after the change is unconsciously fitted to the already known result, and you see what the model answered and write an evaluation criterion that accepts exactly that kind of answer. This is an illusion of control, because you are effectively checking not whether the system does what it should, but whether it is consistent with itself. It is like a teacher first looking at a student’s answers and then writing the questions to match them, in which case the exam will always be passed by everyone.
It is important to understand that the evaluation dataset does not need to be huge from day one. Start with twenty to thirty key scenarios covering the most critical functions, then add new ones as you discover gaps. After a few months you will have several hundred scenarios that describe the behavior of your system.
Three Concepts as a Single System of Thinking
What is interesting about these three concepts is that they do not simply complement each other but form a consistent order of thinking that is applied every time something goes wrong in an AI system. And this order cannot be violated, because each subsequent step relies on the result of the previous one.
When something goes wrong, the first question is: where exactly? This is the job of the AI testing pyramid: to diagnose where the problem lives, whether it is in the model itself, in the pipeline built around it, or in the product experience of the user. Without an answer to this question, you risk optimizing the wrong thing in the wrong place.
Once you have answered the first question, you move to the second one: how bad is it and how do you measure it? This is the job of the composite evaluation pipeline. The important thing here is not simply to acknowledge that a problem exists but to get a numerical assessment of its scale through deterministic checks, semantic similarity, or an LLM Judge, depending on what needs to be checked.
And finally, the third question is: how to lock in the improvement and make sure it does not disappear? This is the territory of EDD. An evaluation dataset written before development gives you confidence that the change is real and not illusory, and that it continues to work.
Together, these three tools turn AI testing from an intuitive activity into a systematic engineering practice. This is especially important for those coming into AI testing from classical QA, not because old skills are useless, but because they need to be supplemented with new tools of thinking. The ability to decompose a problem, build test cases, and think about edge cases all remains necessary. But now it is joined by an understanding of the probabilistic nature of neural networks, the ability to work with numerical scores instead of binary pass/fail results, and the capacity to build evaluation systems that scale together with the product.
March 2026