What is DataOps and How to Start DataOps in Your Organization

Data is the equivalent of gold in today’s modern world. By selectively “mining” data, we can not only analyze the past and draw conclusions, but predict and forecast future events with a reasonable degree of accuracy. All this allows us to make tactical and strategic business decisions on evidence-based information. The importance of data is growing with the development of Big Data technologies, artificial intelligence, machine learning, and the Internet of Things.
That’s why a chaotic approach to data management inevitably drags companies down and pushes them out of the competition. You need organized processes and a clear structure to bring value from your data and make it work for you efficiently.
In this article, we’ll talk about what DataOps is, what it is based on, and what first steps you need to take to start implementing DataOps within your organization.
Key challenges with Data
Even though the potential upsides for any business having a data-driven culture is no secret anymore, many companies still struggle with extracting value from their data efforts. Let’s look at the most common challenges that organizations face today with their data initiatives.
- The growing volume and velocity of Data
The more digital our world becomes, the faster and more data we can register and collect. This requires both high technological capacities and careful, time-consuming processing. Without proper processing and analysis, the accumulated information will just remain data that does not carry any value.
- The complexity of Data Pipelines
Within the same organization, data can be collected from a myriad of different sources, come in different forms, be stored in different repositories, and serve a wide variety of purposes. All this creates complex data pipelines that require highly skilled and careful engineering.
- Management of sensitive Data and Data Governance
Datasets can have different levels of access and requirements for management, publicity, and depersonalization. Failure to comply with these rules may result not only in serious reputational risks, but also legal liability.
- Accuracy and Quality of the Data
Along with the increase of the volume of data, the amount of tasks of its quality assurance also increases. Invalid or corrupted data can lead to incorrect conclusions and analysis, which not only deprives the opportunity to make sound business decisions, but can potentially bankrupt an organization by investing in the wrong direction.
- Growing demand from the business side
Business demand for data, reporting and analytics is growing. Different departments need to solve different problems with data. To bring maximum value, data must be provided in a timely manner, otherwise it will become unrepresentative and lose its inherent business value.
- Lack of experienced specialists and burnout of existing staff
Market demand for data professionals still far outstrips the number of subject matter experts. Employees within companies begin to feel burned out due to the high number of urgent requests, insufficient resources to complete these tasks, and the amount of manual work.
- The Data team becomes a bottleneck
All of these factors lead to the fact that the data team becomes a bottleneck in business processes. This reduces the efficiency of the entire organization, does not justify the high costs and raises questions from the management team, and ultimately leads to customer dissatisfaction.
In order to achieve a true data-driven culture, most companies cannot rely on their own Data Management with the work of a few specialists in an unstable environment. A clear and holistic approach for the entire organization is needed. This is where we come to the concept of DataOps.
What is DataOps?
The term DataOps was first introduced back in 2014 by Lenny Liebmann, Contributing Editor of Information Week in a blog post on the IBM Big Data & Analytics Hub. It started gaining traction in 2017 and was first named on a Hype Cycle for Data Management by Gartner in 2018.
Though DataOps has been around for several years now, today we’re seeing its rise to wider acceptance. In the 2022 Hype Cycle Gartner predicts that DataOps will fully penetrate the market in 2-5 years.
Let’s take a look at a couple of the most popular definitions of DataOps:
“DataOps is a collaborative data management practice focused on improving the communication, integration and automation of data flows between data managers and data consumers across an organization.”
-Gartner
“DataOps is the ability to enable solutions, develop data products, and activate data for business value across all technology tiers, from infrastructure to experience.”
-Forrester
“DataOps is a data management method that emphasizes communication, collaboration, integration, automation and measurement of cooperation between data engineers, data scientists and other data professionals.”
-Andy Palmer, who is associated with popularizing DataOps
Notice how all of these definitions go beyond technologies? DataOps is not a magic tool you can buy and resolve all your problems associated with data. This is not something only for the consideration of your Data teams, but it’s the responsibility of the entire organization. DataOps emphasizes collaboration, integration, communication and experience. Experts often say that it’s more of a holistic mindset or culture that helps data teams and people work together for optimum results.
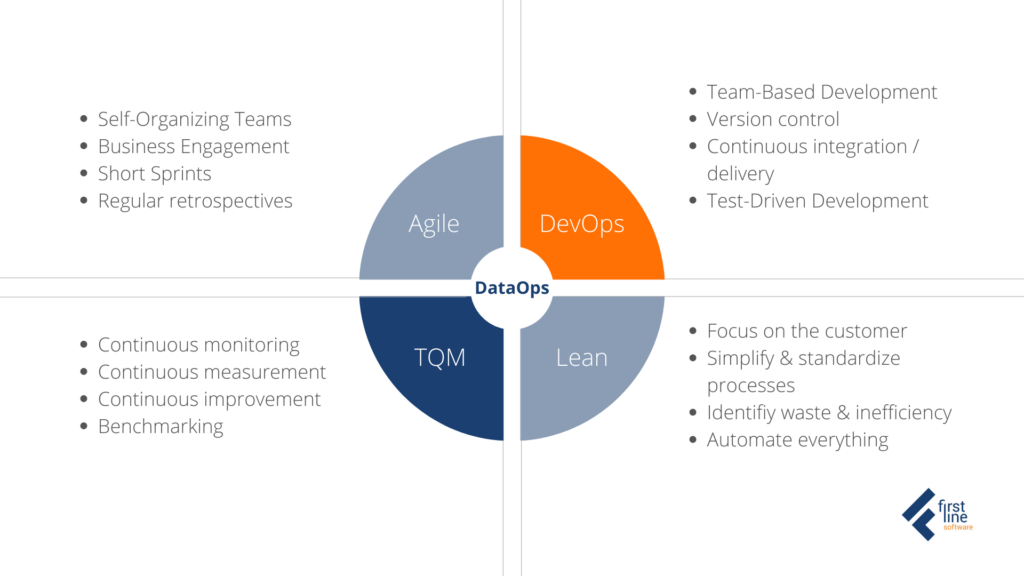
The four disciplines of DataOps
To better understand what DataOps is, let’s take a look at the intellectual heritage that it brings into the data domain. DataOps is based on 4 disciplines, taking the best principles of each and applying them to the data analytics development and operations: Agile, DevOps, TQM (Total Quality Management), and Lean.
Agile Development
Applying Agile Methodologies, self-organized Data teams work closely with subject matter experts and end users. New or updated analytics are published in short periods of time called “sprints”. With these rapid intervals, teams can continuously reassess priorities and adapt to evolving and changing requirements, all based on feedback from users. Each sprint ends with a retrospective which leads to continuous improvement. According to studies where Agile Development replaces the traditional Waterfall methodology – projects are completed faster with less mistakes.
DevOps
As the name suggests, the main roots of DataOps come from DevOps. The term DevOps originally comes from the software engineering space. It combines development (Dev) and IT operations (Ops) to speed up the build life cycle of high-quality software products. The principles and tools created within the framework (GitHub, CI/CD tools and others) proved to be so successful that they began to be adopted in other areas. Some of DevOps best practices used in DataOps are:
- Source control
- Continuous Data Integration
- Separated test and production environments
- Continuous Delivery
Lean manufacturing
The lean methodology comes from the Japanese manufacturing industry. The main focus of the approach is to minimize waste and extra steps while maintaining productivity. Here we can think of data pipelines as production lines in a “data factory”. Data comes from one side of the pipeline, goes through a series of steps and transformations to be converted into reports, models, and views on the other side. DataOps orchestrates, monitors and manages this data factory. As we said before – data pipelines today are incredibly complex, we should use every opportunity to simplify them, which will help to simplify their automation as well.
Total Quality Management
Total Quality Management (TQM) is a continuous process of detecting, reducing and eliminating errors in production, supply chains, customer experiences and it ensures that employees receive training updates on time. Like TQM, DataOps supports continuous testing, monitoring, and benchmarking to identify mistakes before they become major problems.
Each of the four disciplines emphasizes its own outcomes. Eckerson Group in their report, Best Practices in DataOps notes that in the real world it is difficult to put equal effort in each discipline of DataOps. Usually we see that different companies play off different angles depending on their current situation and goals. Some may focus on test-driven development and continuous monitoring with TQM dimension, while others want more of orchestration and automation putting stress on Lean.
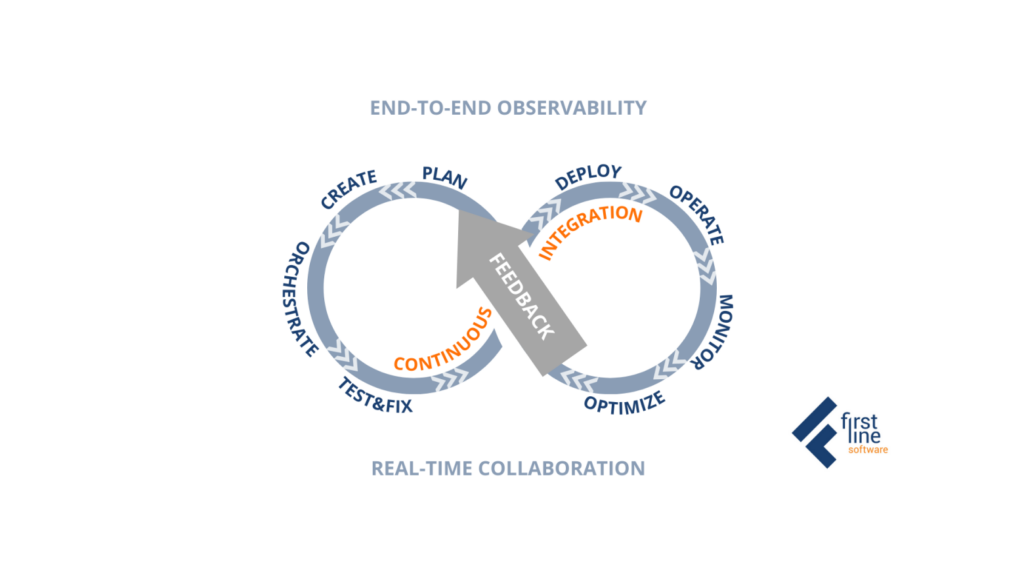
DataOps Framework
Although we described all these disciplines separately in the actual DataOps process, they are part of the same continuous process or loop. As you can see below this loop connects not only development and operations as part of the technical team, but shows connection with business people who are the final customers of the created products.
Why You Need DataOps
So what are the key benefits of deploying DataOps in your organization?
- Faster Cycle Time. DataOps will allow you to significantly reduce data science application cycle time and provide real-time insights to your business people and customers with increased velocity.
- Fewer Defects fromTrusted Data. DataOps ensures high data quality and significantly reduces error rates by focusing on improving data cleansing, usability, completeness, and transparency.
- Efficiency and Agility. DataOps principles allow companies to easily adapt their project pipelines to changes in data, priorities, or requirements. It helps to sustain efficiency and reduce pipeline’s time-to-value.
- Data Democratization. DataOps unlocks access and promotes usage of Data across all people in the organization from the executive teams to every department worker. Enriching your divisions with Data will definitely enhance their results and your ROI.
- Improved collaboration. DataOps encourages collaboration and continuous integration between Data teams, various departments and end users.
- Strong Security and Conformance. DataOps enables organizations to enforce security and governance, and eliminate risks of sensitive data leaks.
First steps for DataOps Implementation
All of this sounds great, but does it appear a bit complex? Here are some first practical steps you can take to start DataOps within your company.
Organizational steps
Identify your bottlenecks. Get your team together and tell them about your plans. First thing you need to find out is – are there major bottlenecks at the moment? What is creating them? Is it people? Lack of technologies or skills? Processes that need to be re-engineered?
Educate your team. Share with your team what you’ve found out about DataOps and explain the main principles of the approach. To encourage people, tell them why you think it is important, what goals you plan to achieve with the DataOps, and how they can benefit from that in their daily work.
Optimize processes. Look at the bottlenecks you’ve identified with your team. How can you break through them? How can processes be optimized?
Debrief regularly. Sometimes you have to take one step back to take two steps forward. Take your time and debrief. What has been done? What went well and what needs improvements? How could you do it cheaper / better / faster?
Monitor your improvement. One of the main principles of DataOps is continuous improvement. Track your progress and keep figuring out possible ways to do things better.
Technical steps
Componentize your code. Move into the direction of microservices, simplify your code.
Build test for every code block. Test on the input, test on the output. There is no single answer on how many tests you should run for one code block. But always remember – the more tests – the better.
Treat Data as Code. Database artifacts are similar to database images. Data in a database can also be turned into an “artifact”. With this artifact, you can store it somewhere, version it, share it with people, and so on. Data is an asset that can undergo various transformations, and you can write code to fix and transform the data. Another characteristic of data as a code structure is that you can “replicate” the code to create a data asset. It’s like using packaged code and applying that code to your infrastructure. You can do the same with a dataset and “store” that dataset somewhere in a repository.
Invest in tools. Don’t start with the tools, think of them when you know what you’re trying to accomplish. You may look for tools to support your:
- Code Repository
- Continuous Integration / Continuous Delivery
- Test Management
- Orchestration
- Monitoring
Let’s Discuss!
What do you think about DataOps? Does it look like your organization could benefit from it, or maybe you already have some moderate success but need to go further with the approach?
First Line Software’s Data Engineering team is always ready to discuss how we can support you in your data initiatives. Just send us a short message describing your current situation and what you want to achieve. Our experts will get back to you quickly and the first consultation is free of charge.
Learn more about our Data Management Services.