
Personal ServiceDesk Assistant: A Breakdown of Chaindesk.ai
Senior Service Engineer

In recent years, technological progress has significantly transformed how we interact with information and automate everyday tasks. One of the most notable changes is the emergence of AI assistants that have become indispensable helpers in both daily life and the business environment. With the development and refinement of various artificial intelligence and machine learning technologies, assistants are becoming increasingly intelligent and adaptive to users’ needs.
In various fields, including customer service, technical support, and service management, personal assistants have become an integral part of efficient operations. With a growing demand for innovative solutions in the realm of service maintenance and ServiceDesk, developers are striving to create smart assistants capable of automating processes, improving customer service, and optimizing workflows.
In this note, we will explore one such product that attempts to create a personal assistant capable of learning from your data and integrating it into current ServiceDesk processes – Chaindesk.ai. Let’s delve deeper into the architecture, features, and advantages of this product, and examine practical scenarios of its usage.
Use Cases at Customer Service Domain
In the realm of customer service, applying GPT models to proprietary data has become almost a mandatory solution for enhancing customer service efficiency. The automation of customer query responses becomes more precise and personalized as models adapt to the specific characteristics of company-specific data.
By utilizing historical customer interaction data, accumulated knowledge bases, and unstructured and diverse data sources, GPT models learn to understand the nuances of queries, providing quick and relevant responses. This capability enables the creation of virtual assistants capable of offering customers a higher-quality service experience.
The application of GPT models in customer service also allows for optimizing query routing processes, automation of routine support tasks, responding to frequently asked questions and known issues, and a significant reduction in customer waiting times. Models adapt to the unique language nuances and preferences of customers, thereby enhancing the overall interaction experience with the company.
Combining various AI models, not only of a general nature but also specialized ones, training on different data for various purposes, and applying them with specifically prepared contexts can lead to quite effective solutions. However, it is crucial to handle data sets provided for training different models with great care to prevent “leakage” into final user responses.
Fine-tuning and Development
Models developed based on transformers represent a powerful tool for natural language processing and solving various tasks. However, after their initial training, there is often a need for additional adjustment and “fine-tuning.” This process requires refining models for specific tasks and usage contexts to achieve the required accuracy and efficiency.
In particular, fine-tuning transformers involves working with a limited volume of data specific to a particular domain. This allows the model to better adapt to the unique characteristics of the task or subject area. However, even though fine-tuning can enhance the accuracy and efficiency of the model, it also requires additional resources for this and expert intervention often.
Important to understand that this process is iterative and often endless. During this process, the model is constantly saturated with data, settings are refined, and other models are added that evaluate the results of the original model.
Also, an essential aspect of using transformers is their sensitivity to the formulation of input queries, known as “prompts.” The “art” of modifying prompts for a specific task becomes an integral part of the process of “tuning” transformer-based models. This means that choosing the right language for the query can significantly impact the quality and accuracy of the output results.
Security and Confidentiality
The security and confidentiality of proprietary data are of utmost importance when using artificial intelligence models. One of the critical components of security, especially when using GPT models, is ensuring that data is protected during the training and usage processes. Although different companies may have different approaches to safeguarding their data, it is universally acknowledged that preventing data leaks during the training and use of AI models is a top priority.
Large companies, considering potential risks, deploy and fine-tune AI models using their own resources and engineering personnel. Recently, pretrained open-source models have also been increasingly used as a foundation.
While open-source AI models offer flexibility, there are inherent risks in deploying and fine-tuning them. Companies should be vigilant about potential security vulnerabilities in open-source code and regularly update their models to address emerging threats. Lack of official support and documentation could pose challenges, making it essential for organizations to have an experienced team capable of addressing issues independently. Moreover, companies need to be aware of licensing implications, ensuring compliance with open-source licenses to avoid legal issues.
Another pole on the security map is the use of commercial models provided to end-users as a service.
Users can take several measures to ensure data protection when employing these. Firstly, thoroughly review and understand the data handling and security practices outlined in the service provider’s policies. Prioritize vendors with robust security certifications and compliance with industry standards. Additionally, implement proper data anonymization techniques before sharing information with the service, minimizing the risk of unauthorized access. Regularly audit and monitor the data flow and access within the service to detect and address any potential security breaches promptly.
Read more: AI for IT Support: Navigating the New Frontier
Example of an AI-assistance tool – Chaindesk
The company Chaindesk.ai describes its own product as an innovative way to interact with its data and extract necessary information using artificial intelligence.
A brief overview of the product’s capabilities is as follows. System administrators create Repositories by populating them with data from various sources or integrations, mostly proprietary. Based on these repositories, they can implement Agents (mean Virtual Assistants) that interact with users through chats. Agents, leveraging knowledge of the data from the Repositories, generate responses to user queries using OpenAI’s LLM models. They do this based on knowledge of internal data, in a human-like manner, in the language in which the question was asked. If there are references in the data used to train the model, they will be provided to the user.
The product can currently utilize the following sources of proprietary data for training:
- The ability to upload data from existing office documents: MS Word, Excel, PowerPoint, PDF, Markdown, and Plain Text.
- When given a link to a website or online resource, crawling data available on it is possible.
- Integration with a range of products: Notion, Zendesk, Google Drive, Slack, WhatsApp, and others.
- An API is implemented, allowing manipulation of data not supported by integrations.
An important distinguishing feature of the product from others is that it is a no-code solution. Additionally, the product includes features for improving responses and retraining Agents providing technical experts with the opportunity to interact with models in the fine-tuning process and refine prompts for specific conditions.
Architecture, Integrations
The product can be used both as a service and as an on-premises solution. When using the service, the capabilities of Chaindesk.ai located in a data center in France are utilized, and transmitted data is also stored on the company’s servers.
Internally, the product employs a set of core technologies, including advancements from the popular Langchain framework, the ChatGPT Retrieval Plugin, and the PostgreSQL and Qdrant databases.
However, the system can be deployed on your infrastructure. In this case, data storage can be restricted according to corporate requirements and controlled internally.
Another crucial element of the system is the integration with the API of the company’s LLM models – OpenAI’s ChatGPT-3.5-Turbo, 4, and 4-Turbo.
Let me illustrate the workflow of using this product. Initially, you need to build a knowledge base using your data. Specify one or more data sources for accessing the information. After loading documents, providing links to web resources, or setting up integrations, the available texts undergo tokenization and then enter the embedding process. The system is now ready to generate responses based on our data.
Moving on to creating an Agent, where internal data sources are accessible to the Agent, the GPT model (which generates natural language responses), the degree of “hallucination capability” in responses, system prompts, and some other parameters can be specified.
Now the Agent is ready for operation and can be embedded in web interfaces or integrated with messengers.
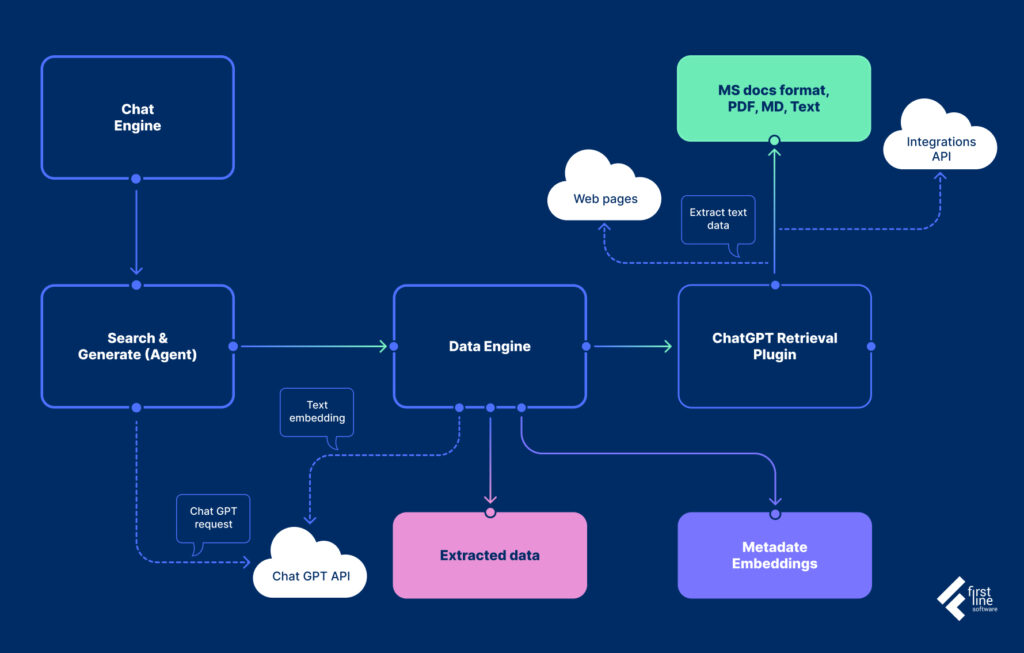
Let’s now discuss how the system works during dialogues with the Agent. The input query is also tokenized initially, and embeddings are formed. A search in the available Agent resources is conducted based on the “similarity” of embeddings. Then a query is made to the GPT model with a preconfigured prompt, the user’s query, and the context formed from the dialogue history and texts found in the “similarity” search. The GPT model, based on the provided data, generates a natural language response that, when presented to the user, is enriched with links to documents found through the “similarity” search.
The final stage of the workflow involves saving each dialogue and passing it to internal employees for further manual analysis if the user indicates that the issue is not resolved. Alternatively, the dialogue can be used for fine-tuning the model.
Pricing
The service offers the flexibility to choose from several system operation plans based on business needs. The free plan is suitable for testing the product’s capabilities. The price for the minimum service plan starts from $25.
Important note, in addition to the mentioned pricing, there are some additional constraints related to the use of available credits in the context of the employed GPT model:
- GPT-3.5 Turbo – 1 credit/query
- GPT-4 – 30 credits/query (premium)
- GPT-4 Turbo – 13 credits/query (premium)
But even the aforementioned expenses are not the only ones. In addition, it is necessary to have a paid account on the OpenAI platform. Each API call to OpenAI ChatGPT will be billed based on the used model.
When processing input data (documents, source code, knowledge bases, etc.) and preparing embeddings, one of the latest OpenAI models, “Text-embedding-ada-002-v2,” is used. The cost will be $0.00010 per 1K tokens. One page of not-very-dense technical documentation can be translated into 400-600 tokens.
When the system generates a response for the user, other models from the ChatGPT family may be involved:
- “GPT-4”. Price: $0.03/1K tokens (Input), $0.06/1K tokens (Output)
- “GPT-4 Turbo”. Price: $0.01/1K tokens (Input), $0.03/1K tokens (Output)
- “GPT-3.5 Turbo”. Price: $0.001/1K tokens (Input), $0.002/1K tokens (Output)
One iteration of dialogue with different models consumes varying amounts of resources, and consequently, the cost will differ:
- “GPT-4” – 1 test dialog interaction: 716 t./145 t. ($0.03)
- “GPT-4 Turbo” – 1 test dialog interaction: 889 t./111 t. ($0.06)
- “GPT-3.5 Turbo” – 1 test dialog interaction: 3741 t./212 t. ($0.01)
Do you already have an AI assistant in your business?
During several weeks of intensive use of the Chaindesk.ai system, we have gained valuable experience based on real documents and knowledge bases. It’s worth noting that the system demonstrates an excellent ability to understand the context of queries after loading relevant documents. This allows it to provide relevant and substantive answers that not only adhere to formal rules but also reflect the context and content of the studied documents. Additionally, system administrators can control the level of “creativity” in responses for each created assistant, contributing to the management of interaction quality.
Several important advantages of the system should be highlighted. First of all, is the flexibility in configuring prompts for ChatGPT and the ability to fine-tune the system in case of identified “gaps” or distortions in knowledge. This mechanism is a key element for continuously improving the system’s effectiveness over time.
Another important advantage of the system is its initial focus on integration with service desk systems and support teams.
Despite the evident benefits, it’s important to note that some limitations may raise concerns for certain companies considering the use of this product. In particular, the system currently exclusively supports GPT models from OpenAI, meaning that OpenAI may have access to private data, and they could make changes or impose restrictions on the API or pricing policy. This may pose certain risks for businesses.
The modern industry is evolving rapidly, offering various approaches to developing specialized assistants. Experienced companies and technical teams tend to use their specialized solutions based on frameworks like Langchain. By adopting suitable models for the task at hand and incorporating various approaches into their business workflows, including not only general-purpose commercial LLMs but also open-source models and small specialized models, they can achieve better results.
Another aspect of the growing popularity and effectiveness of assistants is the integration of multimodality capabilities into the system, meaning the use of not only text but also images, videos, and audio as input and output data.