 Clinovera
ClinoveraWhy Choose First Line Software?
We are experienced and ready to answer your questions. Here are the most common things leaders ask us:

We are experienced and ready to answer your questions. Here are the most common things leaders ask us:
We understand your concern. RAG is a complex field, but our team can provide hands-on guidance and support throughout the process. We’ll break down the complexities, guide your team through each step, and start with small, low-risk projects. Nobody needs to be an expert from the beginning. We’ll also conduct a thorough assessment of your existing systems to develop a phased integration plan that minimizes disruption.
We can start with a minimal, proof-of-concept model to minimize upfront expenses. As you see results and feel more comfortable, we can scale the infrastructure incrementally. We’ve helped companies implement RAG within various budget ranges and will ensure a manageable and scalable cost structure.
Data quality is crucial, but we specialize in improving it. We’ll prioritize data sources based on impact and implement automated data-cleaning processes. We’ll also fine-tune the model to adapt to improving data quality, ensuring incremental improvements.
As GenAI continues to evolve, rigorous evaluation is crucial to mitigate potential risks and ensure continued client satisfaction. Unlike traditional software, GenAI models can produce unpredictable, harmful, or biased outputs if not carefully designed and tested. We believe a that multi-faceted approach to evaluation is essential to identify, measure, and mitigate these risks, ensuring continued client satisfaction and reliable support.
From a client perspective, RAG works by allowing employees and clients to search for information within the enterprise’s vast dataset and generate relevant content based on their queries. This streamlined process ensures quick access to accurate and up-to-date information.
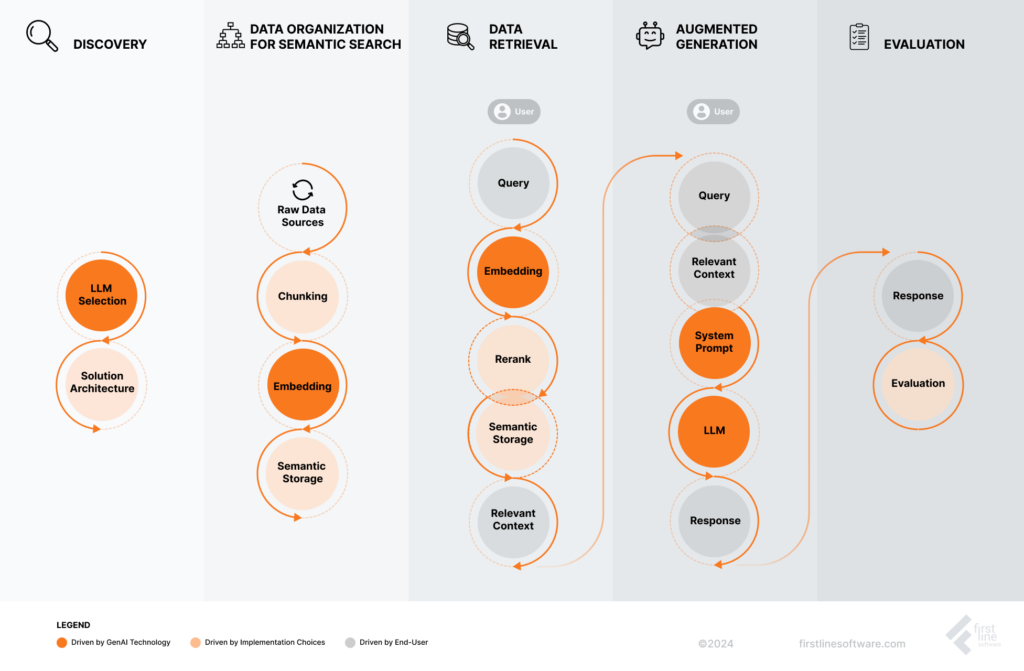
LLM Selection: A suitable language model is selected based on the specific requirements of the RAG system.
Solution Architecture: Appropriate components, such as a language model, retrieval system, and data storage, are selected for the RAG system.
Raw Data Sources: The process begins with identifying and gathering relevant data sources that will form the knowledge base for the RAG system.
Chunking: Breaking down large amounts of data into smaller chunks for efficient processing.
Embedding: The query is converted into a numerical representation (embedding) that can be compared to the indexed data.
Semantic Storage: The system stores and retrieves information based on its semantic meaning rather than its exact keywords or phrases.
Query: A user submits a query or question to the RAG system.
Embedding: The query is converted into a numerical representation (embedding) that can be compared to the indexed data.
Reranking: The results are ranked based on relevance.
Semantic Storage: The system searches through the indexed data using semantic search techniques to find the most relevant information based on the query’s meaning.
Relevant Context: The retrieved information is combined with the original query to form a relevant context.
Query: A user submits a query or question to the RAG system.
Relevant Context: The retrieved information is combined with the original query to form a relevant context.
System Prompt: A prompt is generated based on the query and context, providing the LLM with the necessary information to generate a response.
LLM: A large language model (LLM) is used to generate a response based on the prompt and the retrieved context.
Response: The system provides the user with a response.
Evaluation: The system reviews the system’s performance for future queries.
Retrieval-Augmented Generation (RAG) is a groundbreaking AI technique that combines the power of retrieval-based systems with generative models. This hybrid approach enables the generation of highly accurate and contextually relevant content, making it a valuable tool for various applications.
First Line Software is a premier provider of software engineering, software enablement, and digital transformation services. Headquartered in Cambridge, Massachusetts, the global staff of 450 technical experts serve clients across North America, Europe, Asia, and Australia.



